

Today’s internet users are now used to tools like ChatGPT and Gemini for tasks such as researching products, learning new topics, and more. So, when they visit websites with chatbots, they expect to interact with something just as smart and able to answer all their questions about the business. However, most websites still rely on traditional chatbots that can’t meet these expectations.
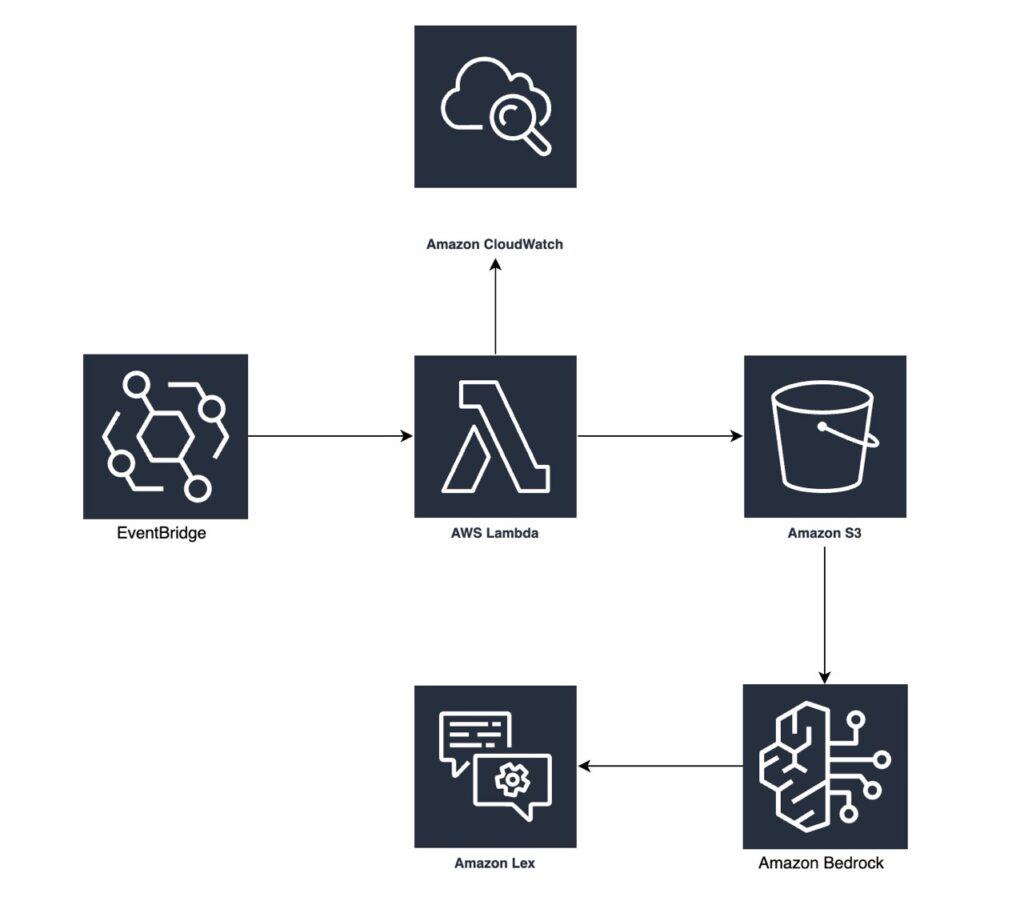
In this project, I will build an AI-powered chatbot that can answer user questions based on the latest content from a website. I used my own site (nilescript.com) to demonstrate all the steps involved. The solution uses a range of AWS serverless technologies, including AWS Lambda, Amazon S3, Amazon Bedrock, Amazon Lex, and Amazon EventBridge.
Now, let’s jump into the project to see how I brought it to life.
Key Technologies and AWS Services Used
- AWS Lambda: Serverless compute for web scraping
- Amazon S3: Scalable and durable storage for storing the raw website content
- Amazon Bedrock: Home for the foundation Models (FMs) and Knowledge Bases for Retrieval-Augmented Generation (RAG)
- Amazon Lex: Conversational AI service for the chatbot interface.
- Amazon EventBridge: Serverless scheduler for automating the the website crawler (lambda function).
- Python: For the Lambda function’s web crawling logic.
The Problem: Static Information, Dynamic Needs
My website, like many others, has constantly changing content such as blog posts, service descriptions, FAQs, and more. Manually updating a chatbot or FAQ section each time something changes is time-consuming and often leads to inconsistencies.
Using LLMs like ChatGPT, which are trained on general world knowledge, to learn about specific website content isn’t a practical solution. They may not provide in-depth or accurate information. For example, if I want to understand the details of a particular aspect of a company, they might not have all the necessary information. Without specific context, LLMs often give vague answers or make things up.
The goal of this project was to:
- Automate content ingestion: Regularly pull the latest information from the website
- Centralize knowledge: Create a reliable, searchable repository of this content
- Enable intelligent Q&A: Allow users to ask natural language questions and receive accurate answers derived directly from the website’s content
The Solution: A Serverless RAG Pipeline
I designed and implemented a serverless architecture to address these challenges. In this section, I’ll dive into the details of how I used each service to achieve the goals mentioned above.
AWS Lambda (NilescriptWebCrawler)
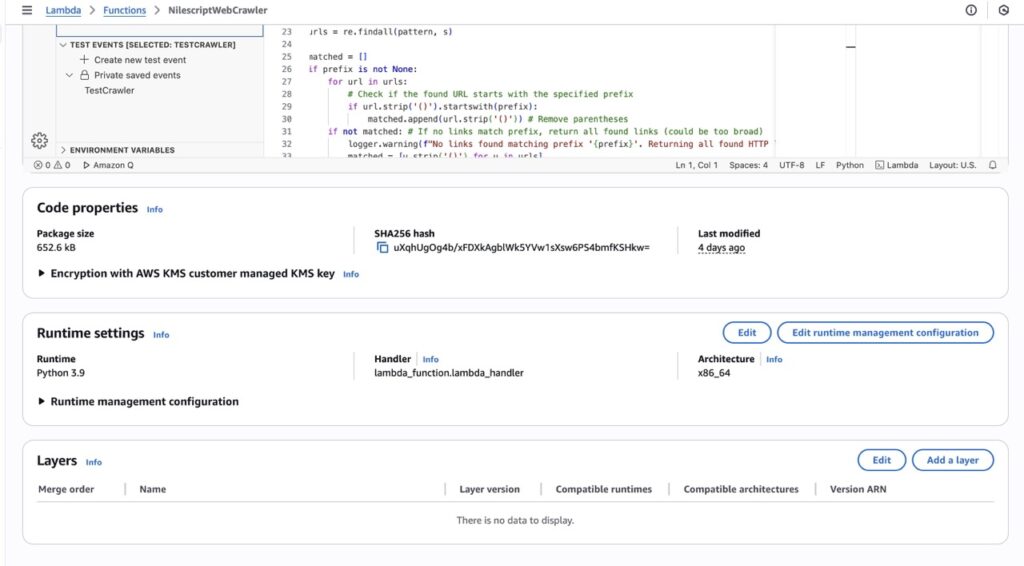
I used a Python-based Lambda function to act as the web crawler. To ensure it worked effectively, I used libraries like requests for making HTTP requests and BeautifulSoup for parsing HTML. These allowed the function to systematically navigate specified URLs on the website and extract relevant text content, which was then saved to S3 as .txt files. The key details of the Lambda function are shown in the screenshot above.
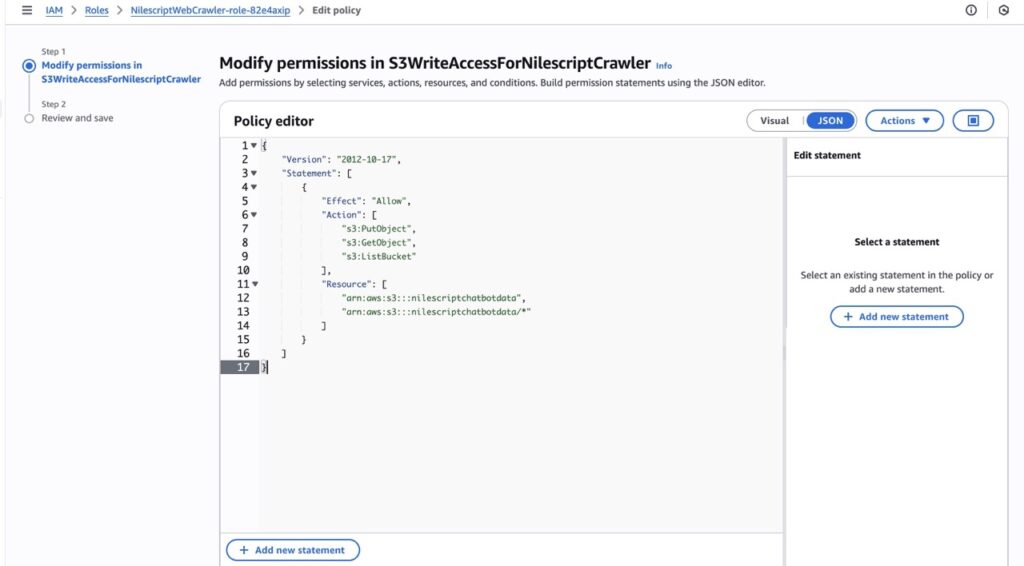
Also, instead of hardcoding the S3 bucket name into the function, I used environment variables. This makes it easier to update the bucket if the destination for ingested data changes in the future. To ensure proper access to the S3 bucket, I created an inline policy under the default role that was automatically generated when the function was created. Details of this are shown in the above screenshot.
Amazon S3 (nilescriptchatbotdata)
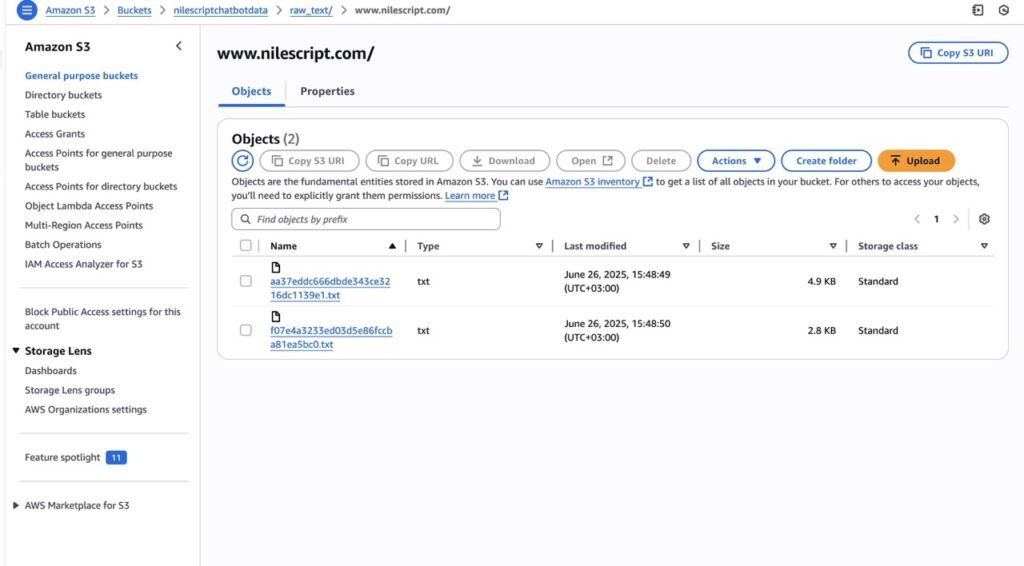
The extracted text content from the website is stored as .txt files in a dedicated S3 bucket (nilescriptchatbotdata). S3 offers a highly available, durable, and cost-effective storage solution. The crawler saves the files under the raw_text/ prefix for better organization. The details of the S3 bucket (nilescriptchatbotdata) I created are shown in the screenshot above.
Amazon EventBridge (NilescriptCrawlerTrigger)
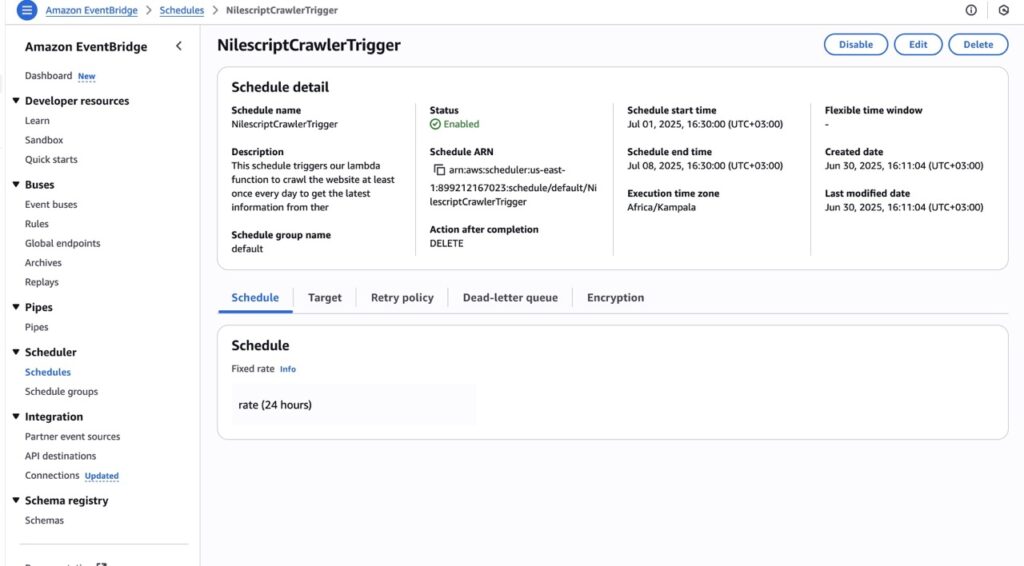
To keep the chatbot’s knowledge up-to-date, an EventBridge schedule was set up. This schedule automatically triggers the NilescriptWebCrawler Lambda function every after 24 hours, allowing it to crawl the site and collect any newly added content. This removes the need for manual updates. The screenshot above shows all the key details of the EventBridge schedule.
Amazon Bedrock Knowledge Base (NilescriptChatbotKB)
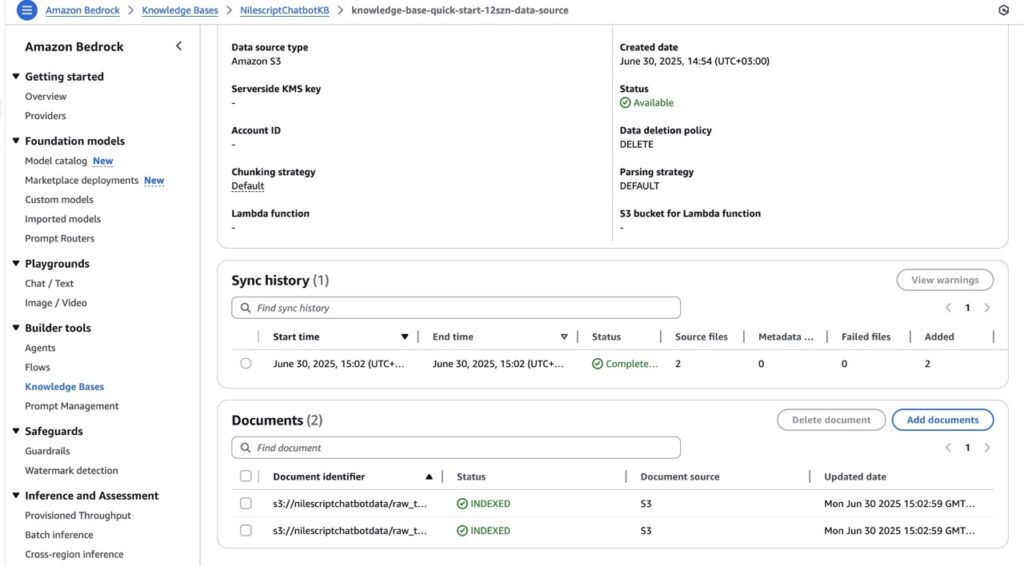
This is the heart of our intelligent Q&A system. I created a Knowledge Base in Amazon Bedrock, pointing it to the raw_text/ prefix in the nilescriptchatbotdata S3 bucket.
During the Knowledge Base synchronization, Bedrock automatically processes the .txt files. It chunks the text into smaller, manageable pieces (such as 512 tokens with 100 token overlap). It then converts these chunks into numerical representations (vector embeddings) using the Amazon Titan Embeddings G1 – Text model, and stores these embeddings in an automatically provisioned Amazon OpenSearch Serverless vector store.
When a user asks a question, the Knowledge Base performs a semantic search on the vector store to retrieve the most relevant text chunks from the website. These retrieved chunks, along with the user’s query, are then sent to a powerful Foundation Model (I used Anthropic Claude 3 Sonnet) to generate a concise and accurate answer that is based on website’s specific content. This RAG approach significantly reduces “hallucinations” and ensures factual accuracy.
Conversational Interface (Amazon Lex)
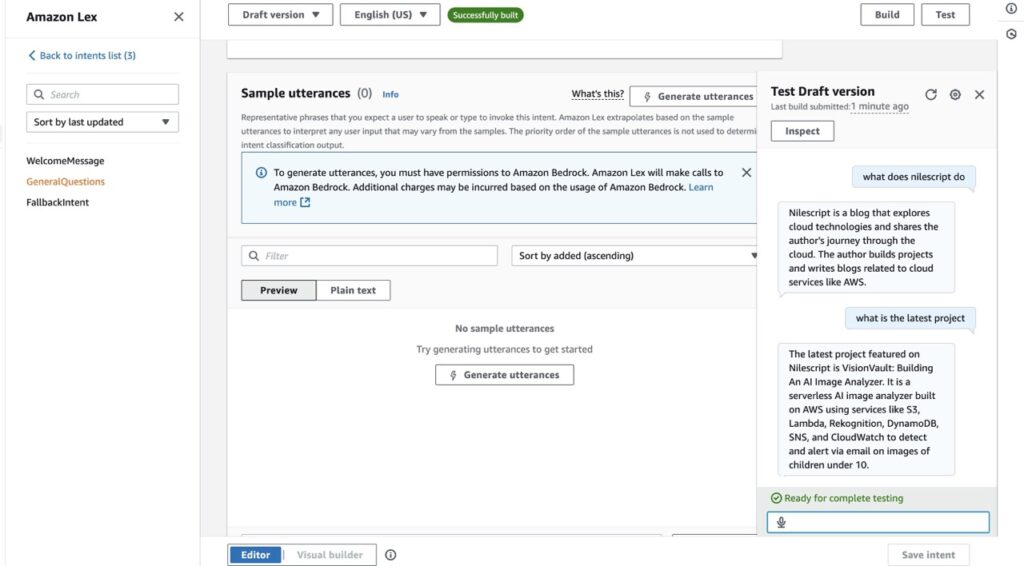
After creating our knowledge base, the final step was to build an interface that we could use to interact with the data—such as asking questions. For this, I created an Amazon Lex bot configured with the English (US) locale.
I also created two intents: a greeting intent and a general questions intent (powered by our Bedrock knowledge base). The bot chooses between these two intents depending on the user’s question. Once both intents were created and built, I tested them to see if they worked as expected.
The screenshot above shows my interaction with the GeneralQuestions intent, and you can see that it’s answering questions about this very website. That means it’s pulling data from the text file that contains all the site’s information that is updated every day.
Challenges and Solutions
This project gave me several common but valuable learning opportunities. Let me share the two that frustrated me the most—until I later figured out their (surprisingly simple) solutions:
- Lambda Timeout: Initially, the Lambda function timed out (default 3 seconds) due to the nature of web crawling that usually takes longer than the default 3 seconds. I fixed this by increasing the Lambda timeout to five minutes to allow sufficient time for scraping and S3 upload.
- Lex Build Errors (Confirmation Prompt): I also encountered an error about a missing promptSpecification in intentConfirmationSetting. I fixed this by disabling the”Confirmation” setting for all intents as confirmation prompts were not necessary for this Q&A chatbot’s flow.
Conclusion
This project offered several learning opportunities, especially since I was using services like Amazon Bedrock and Lex for the first time. It was exciting to see the chatbot working in the final step—I could ask it questions about my site, and it answered them accurately.
Since this was just an experimental project, I deleted the resources after testing to avoid unnecessary AWS costs. In fact, I was charged over $20 after leaving it running for a couple of days. I would recommend doing the same if you are just doing projects for learning purposes.
In a production environment, additional steps could be taken to improve the architecture of this system. Some of these may include:
- User Interface Integration: Deploying the chatbot on a public web page using the open-source Amazon Lex Web UI project, which provides a customizable chat widget that connects to the Lex API.
- Secure Public Exposure with API Gateway: Unlike the Lex console testing interface, a production chatbot needs to be accessible via a web application. This would involve setting up an Amazon API Gateway endpoint to securely expose the Lex bot.
- More Security Best Practices: Applying stricter IAM policies based on the principle of least privilege and using AWS WAF to protect the API Gateway endpoint from common web threats.
That’s it for this project—I’ll be back with the next one later this week!
